美元下跌非農爆冷,貴金屬王者歸來 黃金“一飛沖天”后的市場思考與投資者教育
國際金融市場波瀾再起。美元指數走弱,疊加美國非農就業數據意外“爆冷”,為黃金等貴金屬市場注入了強勁的上漲動力。金價如“一飛沖天”,屢創新高,吸引全球目光。面對如此劇烈的市場波動,投資者在驚嘆“王者歸來”的也不免心生困惑:黃金后市將何去何從?作為理性的市場參與者,尤其是普通投資者,此刻更應回歸冷靜思考,尋求專業的市場解讀與投資教育。
一、 市場動態解析:多重因素共推金價
- 美元疲軟提供支撐:美元指數是影響黃金價格的核心變量之一。由于市場對美聯儲未來加息路徑的預期發生變化,美元承壓下行。黃金以美元計價,美元走弱使得以其他貨幣計價的黃金變得更便宜,從而刺激了全球范圍內的購買需求,直接推高了金價。
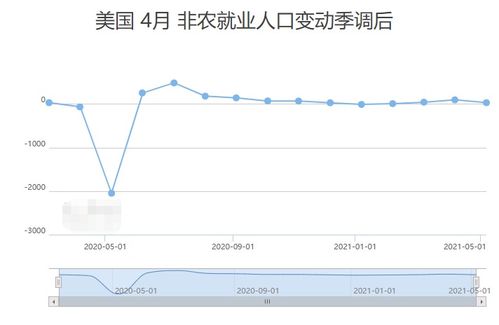
- 非農數據“爆冷”點燃行情:美國最新公布的非農就業數據遠低于市場預期,顯示出勞動力市場可能正在降溫。這一數據削弱了市場對美聯儲將繼續激進加息的預期,甚至強化了未來可能降息的猜測。利率預期的轉變,降低了持有無息資產黃金的機會成本,同時加劇了對經濟前景的擔憂,黃金的避險屬性得以凸顯,引發大量資金涌入。
- 地緣政治與通脹擔憂的長期底色:盡管直接推動此輪上漲的是上述短期因素,但俄烏沖突持續、全球通脹中樞上移、以及去美元化趨勢下的央行持續購金等中長期背景,早已為黃金構筑了堅實的“價值底”。當前行情是這些長期邏輯在特定催化劑下的集中爆發。
二、 黃金“一飛沖天”后,投資者應何去何從?
面對疾馳的“黃金列車”,投資者容易陷入“追漲”的沖動或“恐高”的焦慮。此時,專業的投資決策教育顯得尤為重要:
- 理解驅動邏輯,而非單純追逐價格:教育咨詢服務首先應幫助投資者厘清本輪上漲的核心驅動力——是短期數據擾動下的情緒推動,還是長期邏輯發生了根本性轉變?理解這一點,才能判斷行情是趨勢的起點,還是階段性高潮。
- 樹立正確的資產配置觀念:黃金在投資組合中主要扮演的是“壓艙石”和“對沖風險”的角色,而非博取短期暴利的主要工具。專業的投資教育會引導投資者根據自身的風險承受能力、投資期限和整體資產狀況,理性配置黃金資產比例(通常在5%-15%),避免因單一資產波動過大而影響整體財務健康。
- 熟悉投資工具與風險:投資黃金的渠道多樣,包括實物金條、紙黃金、黃金ETF、黃金期貨及礦業股等。每種工具在流動性、交易成本、杠桿率、風險等級上截然不同。投資者教育需詳細解析各類工具的優劣及適用場景,特別是對于帶杠桿的衍生品(如期貨),必須充分警示其高風險特性,避免非專業投資者盲目涉足。
- 培養獨立思考與風險意識:市場情緒極易傳染。在“一飛沖天”的行情中,更需要警惕過度樂觀的風險。專業的教育服務應教會投資者關注后續的關鍵指標(如CPI數據、美聯儲議息會議、實際利率變化等),并制定明確的入場、離場及止損紀律,管理好預期和風險。
三、 尋求專業教育咨詢服務的重要性
在復雜多變的金融市場中,個人投資者往往處于信息不對稱的弱勢地位。專業的金融教育咨詢服務能提供:
- 系統化的知識梳理:將碎片化的市場信息整合成有邏輯的分析框架。
- 客觀中立的視角:避免受市場極端情緒和銷售導向信息的影響。
- 決策支持與心理按摩:不僅在知識上賦能,更在投資心理和紀律上提供指導,幫助投資者在波動中保持鎮定。
結論
美元下跌與非農爆冷,確實為黃金市場點燃了新一輪的烈火。火焰之后是持續燃燒還是逐漸熄滅,取決于后續宏觀經濟數據的演變與全球貨幣政策的走向。對于投資者而言,“何去何從”的答案,不在于預測市場的精準拐點,而在于通過持續學習和接受專業教育,構建起屬于自己的、理性的認知體系和投資紀律。在貴金屬“王者歸來”的喧囂中,保持冷靜的頭腦和長期主義的視角,才是穿越周期、實現財富穩健增值的真正“王者之道”。
如若轉載,請注明出處:http://www.zglh888.com.cn/product/56.html
更新時間:2026-06-19 01:59:33